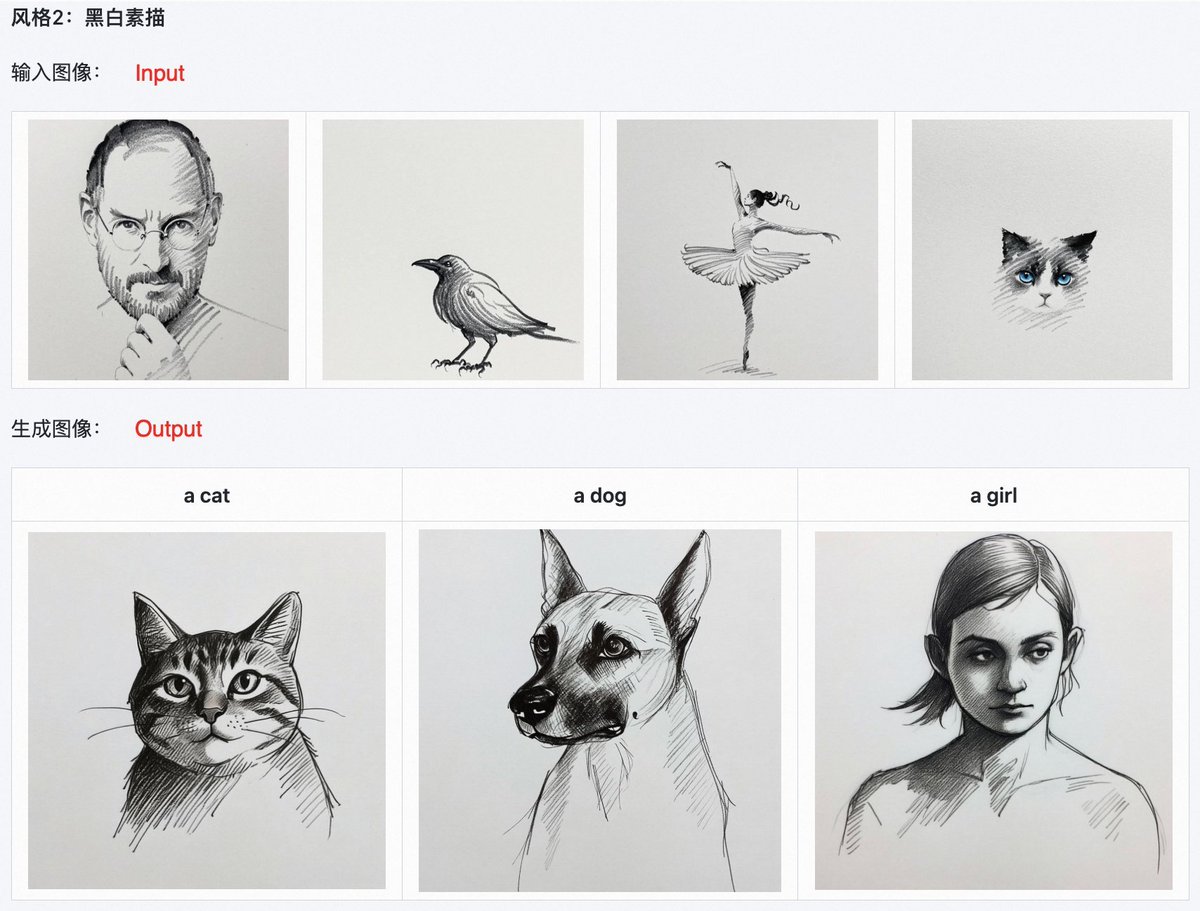
Brothers, this is great! Qwen-Image-i2L: Can "convert any image into a LoRA model". “Give it an image and it can automatically generate a LoRA (a finely tuned AI style module).” You only need to provide a certain art style, character style, or artwork, and Qwen-Image-i2L can analyze the visual features of the image and automatically generate a LoRA module. You can then use this LoRA in other models. Qwen-Image-i2L utilizes the SigLIP2 + DINOv3 + Qwen-VL feature extraction system. Images are decomposed into learnable features such as "style + content + composition + tone". It was then compressed into a lightweight LoRA module. The generated LoRA can be directly loaded into the generative model for use, achieving "single-image style transfer".

Qwen-Image-i2L offers four "model styles" for different purposes: 🎨 Style – Pure aesthetic extraction (2.4B) 🧩 Coarse-grained – Captures content + style (7.9B) ✨ Fine – 1024x1024 Detail Enhancer (7.6B, for use with the Coarse version) ⚖️ Bias – To keep the output consistent with the inherent style of Tongyi Wanxiang (30M)

Case Studies

Detaixiaohu.ai/c/a066c4/qwen-…://t.cmodelscope.cn/models/DiffSyn…nload: https://t.co/UmADMKKHb9
